Architecture overview
This document will discuss the component services that Tator uses in detail, including where they run and how they interact.
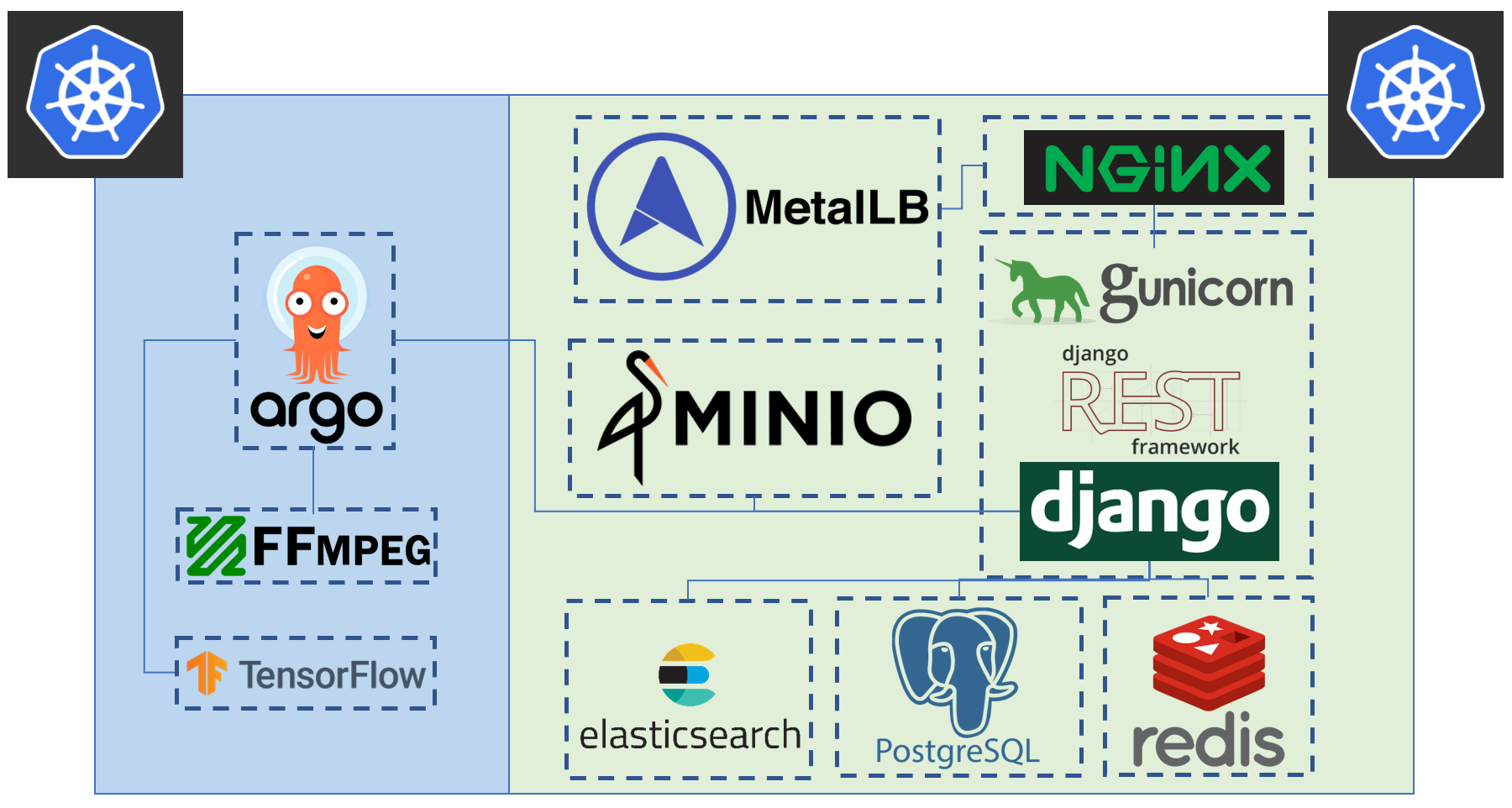 Tator deployment makes use of one or more kubernetes clusters: one for serving the web application, and either the same cluster or other remote clusters for running heavy workloads such as transcodes and algorithms. The green/blue boxes above denote where one can seperate the deployment to two seperate kubernetes clusters.
Tator deployment makes use of one or more kubernetes clusters: one for serving the web application, and either the same cluster or other remote clusters for running heavy workloads such as transcodes and algorithms. The green/blue boxes above denote where one can seperate the deployment to two seperate kubernetes clusters.
Kubernetes
Tator is cloud-agnostic: It runs on bare metal or on any major cloud service provider such as AWS, GCP, or Azure. As a distributed application (an application that runs on multiple physical nodes), it is scalable and highly available. These features are made possible because Tator runs on Kubernetes, a container orchestration framework originally developed by Google. All major cloud service providers provide managed Kubernetes services, and on bare metal we recommend using a distribution of Kubernetes developed by Canonical called microk8s. These services simply make Kubernetes clusters easier to manage and maintain. Kubernetes abstracts away physical hardware and allows Tator to run in containers.
But what is actually running on Kubernetes? It turns out there are only three core, custom Tator workloads running on any given Tator deployment: the Tator REST (Representational State Transfer) API, asynchronous transcodes (video conversion workloads), and maintenance cron jobs which are used for various functions such as database cleanup. Each of these runs in one of the two primary custom container images defined in Tator, respectively: a backend container and a client container. The rest of the software that runs on Kubernetes is either a third-party dependency or a user defined algorithm workflow.
Helm
There are two "add-ons" that we use to make Kubernetes more useful. The first is Helm. Helm can be thought of as a package manager for Kubernetes applications. Packages in Helm are called "charts". All major third-party services maintain a Helm chart or have a community maintained Helm chart. Tator itself is distributed as a Helm chart, and it is through this chart that we define required third party dependencies and manage the configuration of all pieces of a Tator deployment. Helm has many features that help with continuous deployment, such as the ability to rollback application updates and to rollout application updates with zero downtime.
Argo
The second Kubernetes add-on that we use is Argo. Argo allows Tator to execute long running tasks on Kubernetes asynchronously. It is implemented as a custom resource definition (CRD), an extension of Kubernetes. Specifically, it introduces a new Kubernetes object called a "workflow". A workflow consists of a series of steps, each of which is executed in a specified container image. A workflow can be as simple as a single command run in a single container, or a complex directed acyclic graph, complete with step dependencies and parallel execution. The only core workflow that is initiated by Tator is the transcode workflow, which is used to convert videos to a streaming format compatible with Tator's player or to a download-optimized format upon media upload. All other workflows that run in Tator are user-defined custom workflows, which may be algorithms for processing videos or report generation workflows. Transcodes in Tator can be run on the same Kubernetes cluster as the Tator REST API, or on a separate Kubernetes cluster defined via the Helm configuration file. Likewise, custom user-defined workflows can be run on user-defined Kubernetes clusters (and in many cases custom workflows must be run on a separate cluster for security reasons; this requirement can be enforced via a Helm configuration parameter).
Use of managed services
Now we can discuss the various third-party dependencies that run on Kubernetes with the Tator REST API. We can group these dependencies into four functions: serving the application, object storage, databases, and administration. Many of these services may be managed services rather than running on Kubernetes. This can be configured using the Helm chart configuration file, and is the recommended configuration for production deployments of Tator.
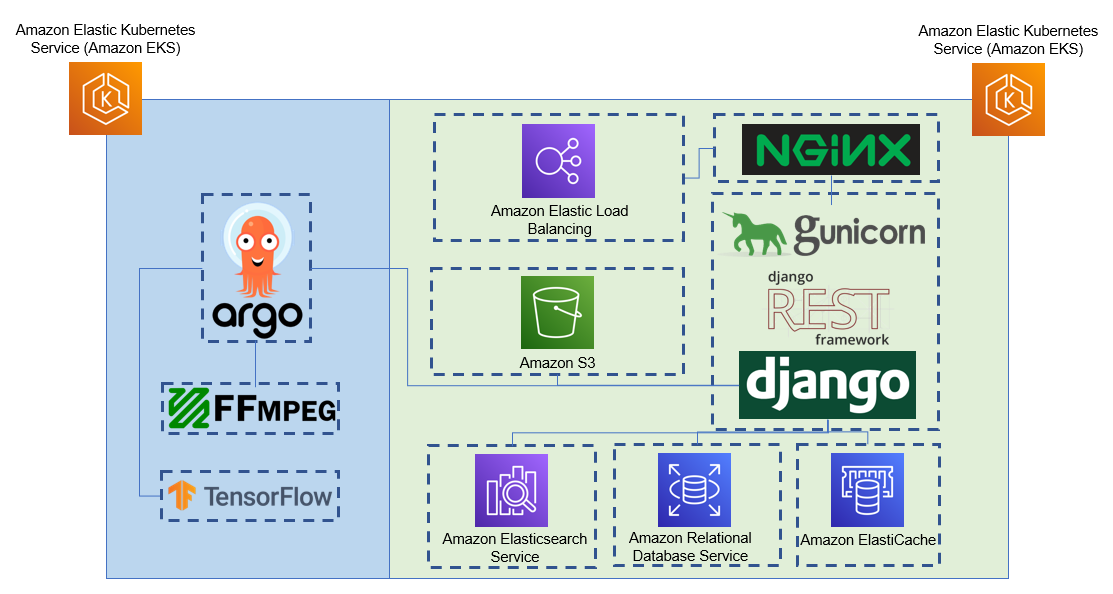 Example deployment architecture leveraging AWS managed services. Tator can be deployed on all major cloud providers (AWS, GCP, Azure) as well as bare metal.
Example deployment architecture leveraging AWS managed services. Tator can be deployed on all major cloud providers (AWS, GCP, Azure) as well as bare metal.
Serving the application
Clients communicate with the Tator REST API using HTTP or HTTPS requests. All of these requests are proxied by NGINX, a web serving application. In the case of HTTPS, NGINX is the endpoint for encrypted traffic; all upstream services are communicated to via HTTP. NGINX is also used for serving static assets, including the front-end code and documentation. In Kubernetes, all applications are implemented as "Deployment" objects, and have a corresponding "Service" object that specifies how the application can be accessed. In the case of NGINX, the service object is of type "LoadBalancer". This means that the service accepts external traffic, routes it into the internal container network, and uses a load balancing strategy to distribute traffic among one of multiple NGINX containers. For cloud service providers, the LoadBalancer object is implemented using a managed load balancing service. For example, on AWS a Kubernetes LoadBalancer is fulfilled by Elastic Load Balancer (ELB). On bare metal, we use an application called MetalLB to implement LoadBalancer objects. This allows Kubernetes to accept traffic on a specific IP address in a local area network using standard routing protocols.
Object storage
Tator uses S3-compatible object storage for files, including media and media attachments. Several services claim to be S3-compatible, but in reality each storage service has minor differences in their APIs. There are three officially supported object storage services in Tator: AWS S3, Google Cloud Storage (GCS), and min.io. Min.io may be run on Kubernetes, either on the same Kubernetes cluster running the Tator REST API or on a separate cluster. It can also be installed on bare metal or in docker containers. There are three "system" buckets that may be defined, only one of which is required. The required bucket is the live bucket; it is where streaming and downloadable media is stored. The second system bucket is the upload bucket. It may be used for storing initial uploads. In general this bucket should be colocated with transcoding hardware. The third bucket is used for archival storage. If this bucket is defined, Tator will use it to back up the live bucket. This is useful in situations such as an on-premise live bucket with cloud-based archival backups. In addition to these buckets, user-defined buckets may be registered in Tator and associated with an organization. A user-defined bucket may be used on any given project in place of the system default bucket for hot storage. The upload and archival buckets may also be user-defined. While requests to the Tator REST API are proxied by NGINX, requests to object storage may be made directly to the object storage service. The only configuration in which object storage requests are proxied are when min.io is running on the same Kubernetes cluster as the Tator REST API (typically only in development configurations). This is made possible by pre-signed URLs which are returned by the REST API, and it results in lower latency media downloads and reduced load on the REST API load balancer and NGINX.
Databases
Tator uses three database-like services for storing media metadata, users, projects, organizations, algorithm registrations, dashboards, and other data. All three of these are interacted with by the REST service, which is implemented using Python, specifically Django with Django REST Framework. The primary database service is PostgreSQL, which is interacted with through Django's Object Relational Mapping (ORM). Model definitions, migrations, and read/write operations all go through the ORM. The second database is Elasticsearch, which is used to mirror selected data from PostgreSQL. Certain query types are much faster in Elasticsearch, such as aggregations and parent/child queries. We select which database to use based on the given request parameters, but the data is always serialized out of PostgreSQL. The third database service is Redis. Redis is an in-memory database that has extremely fast access times, and it is used for storing information about temporary objects, such as workflows submitted to Argo.
Administration
Some dependencies are used only for administrative purposes, namely to monitor the health and correct functioning of a Tator deployment. All of these services run on the same Kubernetes cluster where the Tator REST API is running. This is primarily so that these services have direct access to the pods in the REST API. Logs from all pods running in the Kubernetes cluster are configured to write to Elasticsearch using Filebeat. This uses the same Elasticsearch service that is used for mirroring PostgreSQL. These log records are stored for seven days, and can be accessed via Kibana. Kibana is proxied by NGINX at /logs, and can be accessed only by users who are granted "staff" permissions in Django. For pod metrics, such as number of pods, CPU utilization, and request latency, we use Prometheus. Prometheus aggregates metrics from the Kubernetes API, Gunicorn (the server used internally to serve the REST API application), and NGINX to a persistent volume, and these metrics then can be displayed using Grafana. Grafana is also proxied by NGINX and made available to staff users at /grafana.